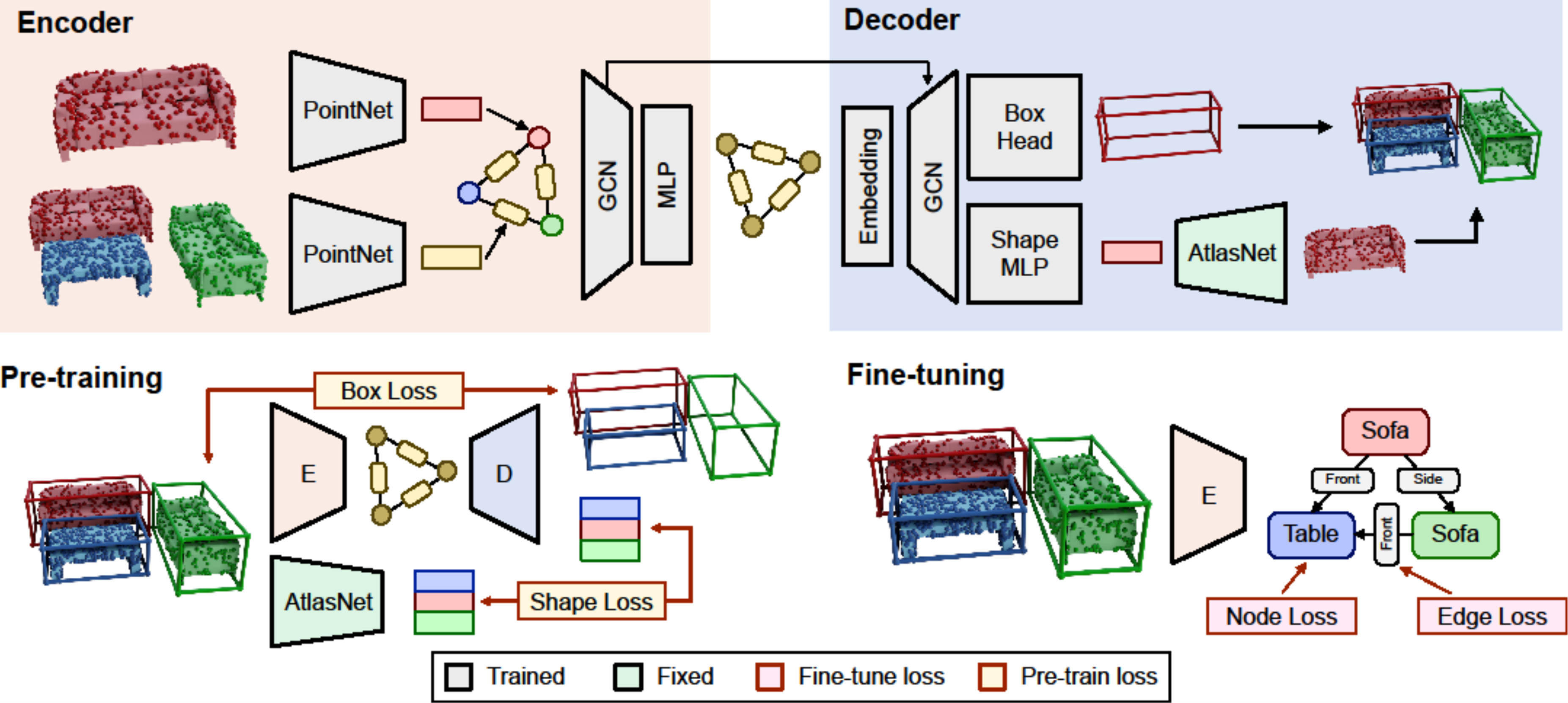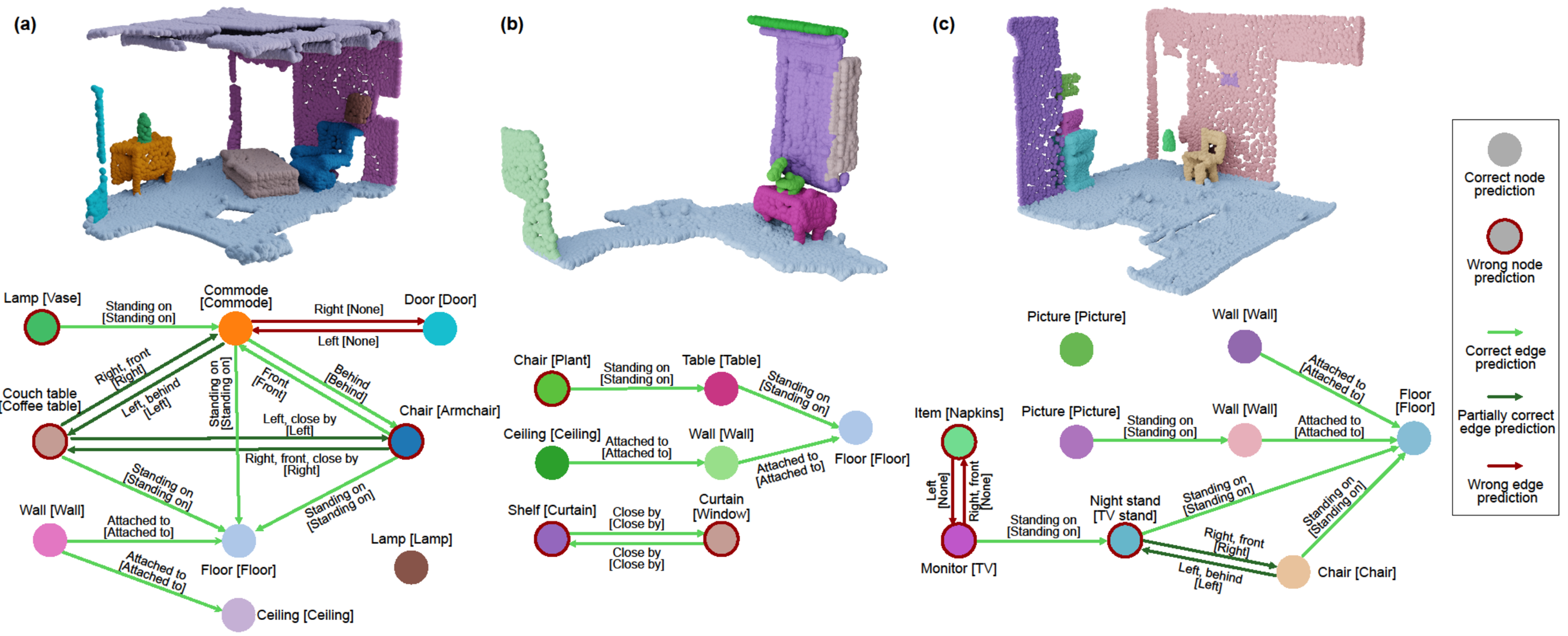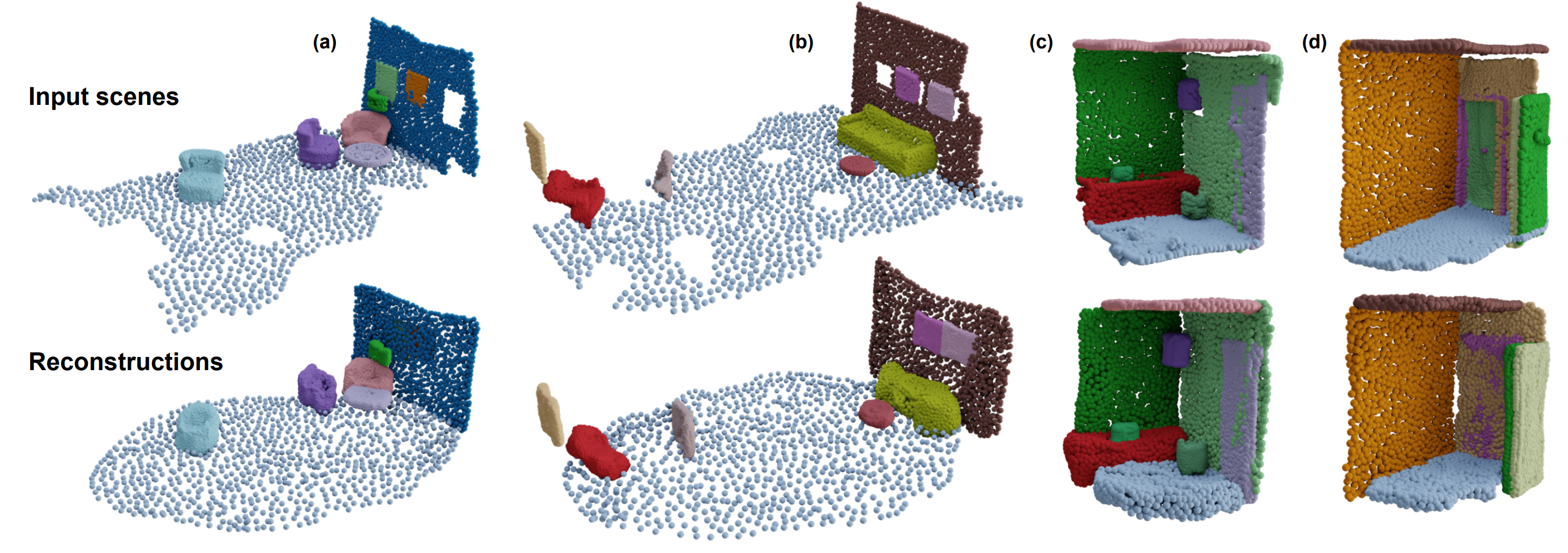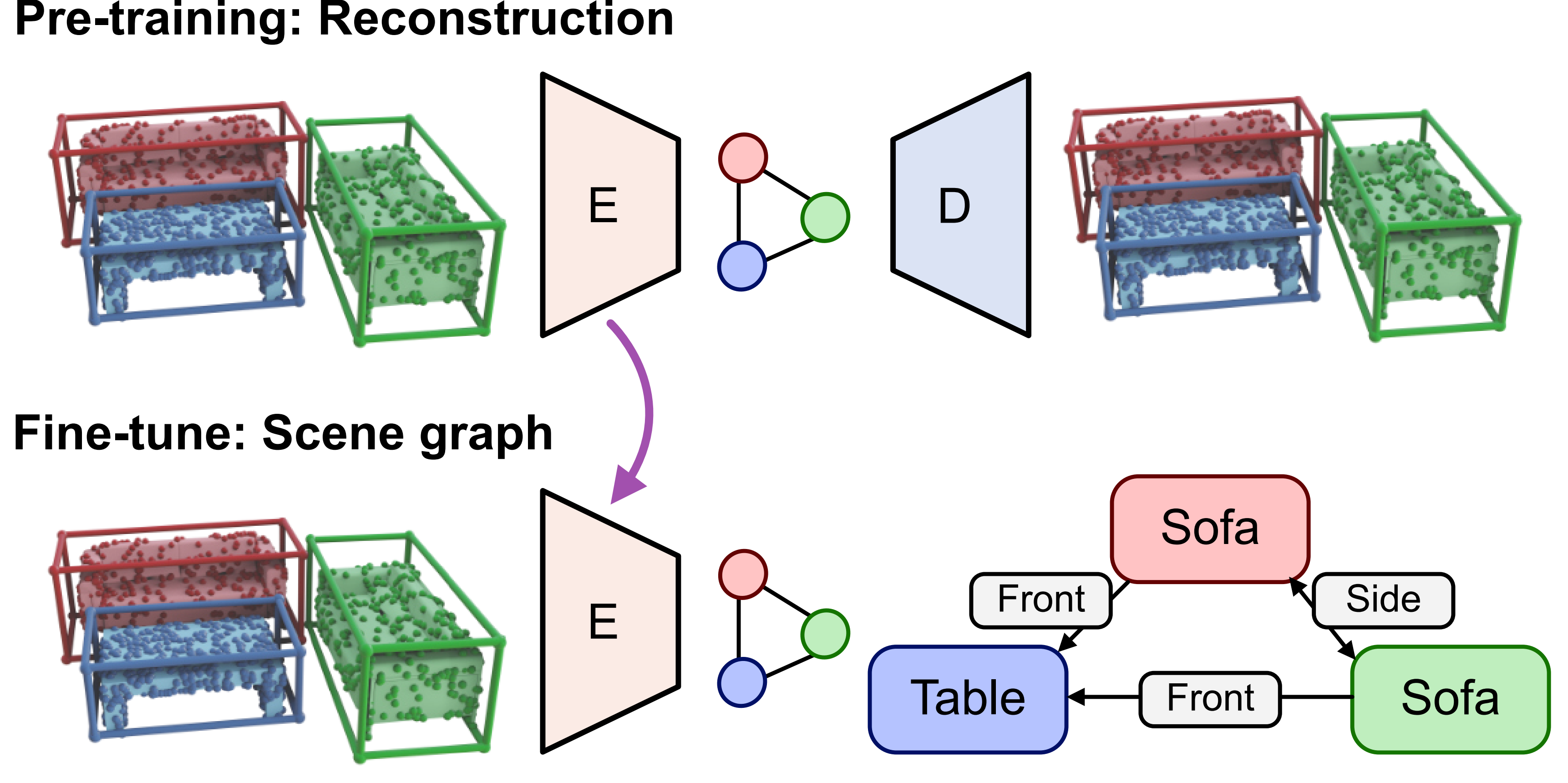
3D scene graphs are an emerging representation for 3D scene understanding, combining geometric and semantic information. However, fully supervised learning of 3D semantic scene graphs is challenging due to the need for object-level annotations and especially relationship labels. Self-supervised pre-training methods have improved performance in 3D scene understanding but have received little attention in 3D scene graph prediction. To this end, we propose Auto3DSG, an autoencoder-based pre-training method for 3D semantic scene graph prediction. By reconstructing the 3D input scene from a graph bottleneck, we reduce the need for object relationship labels and can leverage large-scale 3D scene understanding datasets. Our method outperforms baseline models on the main 3D semantic scene graph benchmark and achieves competitive results with only 5% labeled data during fine-tuning.