 Lang3DSG
Lang3DSG
Language-based contrastive pre-training for
3D scene graph prediction
International Conference on 3D Vision 2024 (3DV)
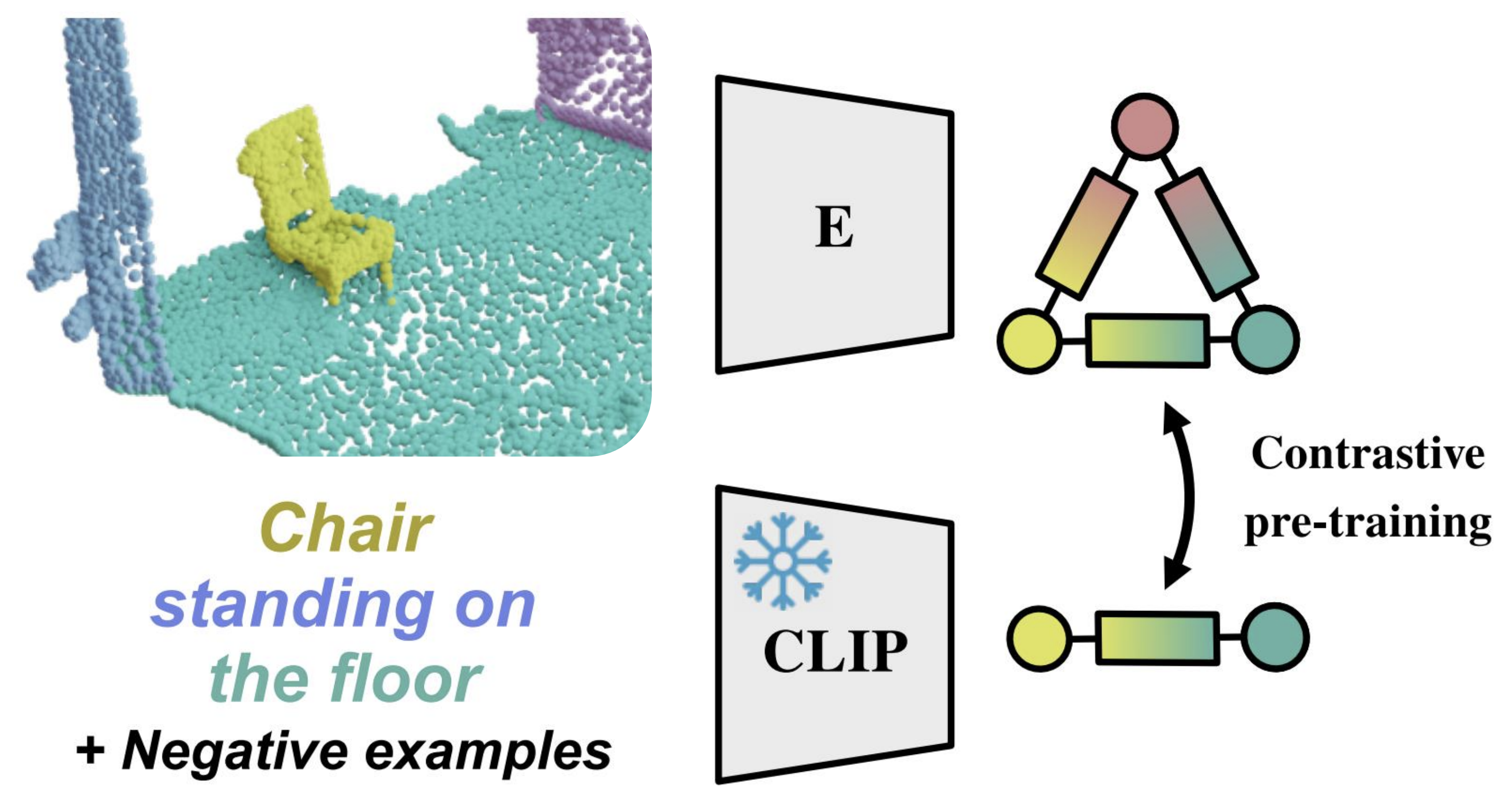
Abstract
3D scene graphs are an emerging 3D scene representation, that models both the objects present in the scene as well as their relationships. However, learning 3D scene graphs is a challenging task because it requires not only object labels but also relationship annotations, which are very scarce in datasets. While it is widely accepted that pre-training is an effective approach to improve model performance in low data regimes, in this paper, we find that existing pre-training methods are ill-suited for 3D scene graphs. To solve this issue, we present the first language-based pre-training approach for 3D scene graphs, whereby we exploit the strong relationship between scene graphs and language. To this end, we leverage the language encoder of CLIP, a popular vision-language model, to distill its knowledge into our graph-based network. We formulate a contrastive pre-training, which aligns text embeddings of relationships (subject-predicate-object triplets) and predicted 3D graph features. Our method achieves state-of-the-art results on the main semantic 3D scene graph benchmark by showing improved effectiveness over pre-training baselines and outperforming all the existing fully supervised scene graph prediction methods by a significant margin. Furthermore, since our scene graph features are language-aligned, it allows us to query the language space of the features in a zero-shot manner. In this paper, we show an example of utilizing this property of the features to predict the room type of a scene without further training.
Video
Method Overview
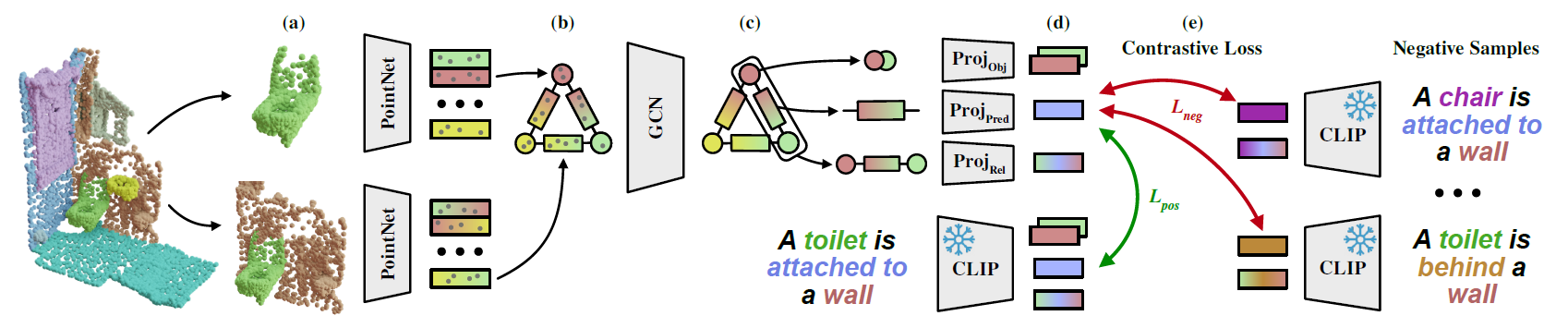 Our method takes as input a class-agnostic segmented point cloud and
extracts point sets of objects and pairs of objects (a). The point sets are passed into a PointNet backbone to construct an initial feature graph
(b). Using a GCN, the features in the graph get refined (c) and node, edge and node-edge-node triplets are projected into the language
feature space (d). Using a contrastive loss, we align the 3D graph features with the CLIP embeddings of the scene description (e).
Our method takes as input a class-agnostic segmented point cloud and
extracts point sets of objects and pairs of objects (a). The point sets are passed into a PointNet backbone to construct an initial feature graph
(b). Using a GCN, the features in the graph get refined (c) and node, edge and node-edge-node triplets are projected into the language
feature space (d). Using a contrastive loss, we align the 3D graph features with the CLIP embeddings of the scene description (e).
3D Scene Graph Predictions
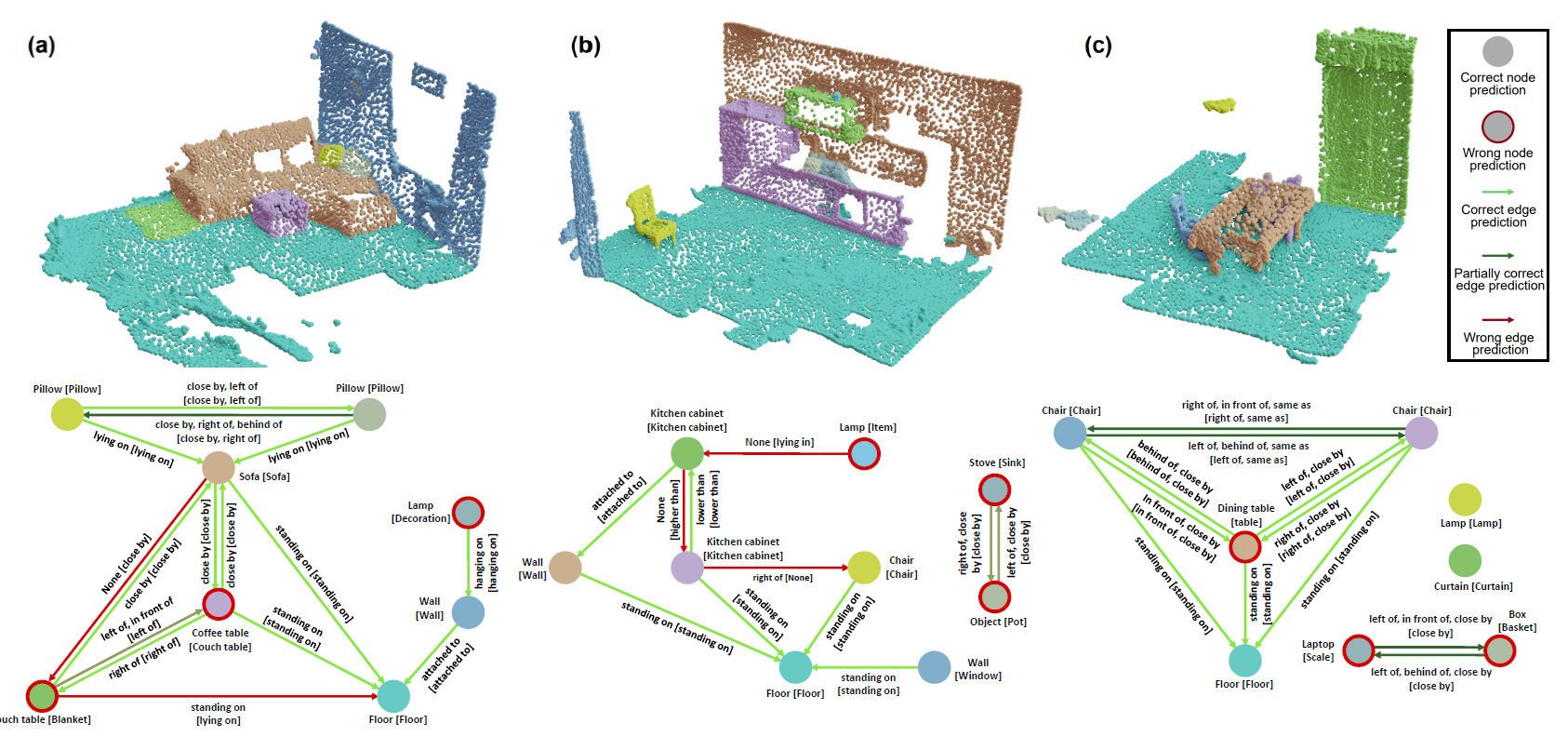 Qualitative results of 3D scene graph prediction with Lang3DSG for
three different example scenes. We visualize the top-1 object class prediction for each node and the predicates with a probability greater
than 0.5 for each edge. Ground truth labels are shown in square brackets.
Qualitative results of 3D scene graph prediction with Lang3DSG for
three different example scenes. We visualize the top-1 object class prediction for each node and the predicates with a probability greater
than 0.5 for each edge. Ground truth labels are shown in square brackets.
Application: Zero-shot room classification
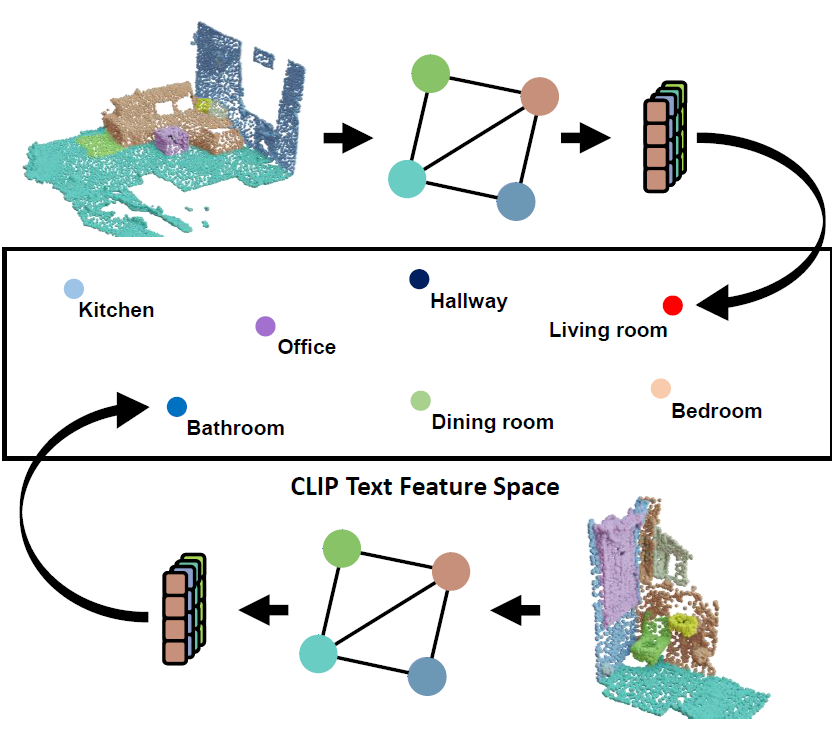
Utilizing the
language-aligned graph features we can classify the room type of
a scene by similarity scoring the feature embedding of a room description
and our 3D graph features.

BibTeX
@inproceedings{koch2022lang3dsg,
title={Lang3DSG: Language-based contrastive pre-training for 3D Scene Graph prediction},
author={Koch, Sebastian and Hermosilla, Pedro and Vaskevicius, Narunas and Colosi, Mirco and Ropinski, Timo},
booktitle={2024 International Conference on 3D Vision (3DV)},
year={2024},
}